This blog post is part of a series summarising my PhD project and the steps to complete my degree. The information in this blog post discusses reinforcement learning techniques that use the custom gripper to leverage environmental constraints while grasping. Refer to thesis for full details.
Introduction
Where We’re At
So far, throughout this series of posts, I’ve outlined how I surveyed previous grippers designed for fabric manipulation to identify unique gaps and produced a novel device that addresses existing limitations to produce a gripper suited to the pick and place of textile waste, as shown below. There were several research avenues to pursue after reaching this stage of my doctoral journey, and I chose to investigate reinforcement learning (RL) approaches towards grasping motions that leverage the environment, also known as environmentally constrained (EC) grasping.

The produced gripper discussed in the previous post.
The three images below display the scenarios where reinforcement learning-based approaches could assist in developing policies that elicit the desired behaviour. The core question central to the research conducted here was how data-driven approaches can encourage the gripper to move the fingertip along an environment surface, producing a protrusion on the body of a garment for the gripper to grasp. Whatever solution is applied would need to perform such an action regardless of the gripper’s orientation relative to the environment surface. Before formulating the problem in an RL context, it’s essential to understand the fundamentals of grasping motions that leverage the environment and how they improve grasp success, which the next section discusses.



Example circumstances where grasping motions that exploit the environment could be applied.
Grasping Robustly by Leveraging The Environment
One of the capabilities that makes humans such adept generalised manipulators is our ability to leverage environmental constraints while manipulating in uncertain conditions. A study demonstrating this notion [Eppner 15] showed how humans would rely on grasps that exploited the environment more often while visually impaired, as the image below shows. The broader literature on this topic also notes how humans improve their grasp success by leveraging the environment [Puhlmann 16, Kazemi 14, Sarantopoulos 18, Santina 17].

An example of a human-centric study evaluating grasps when visually obscured [Eppner 15].
Throughout the research conducted during my PhD, there was a broad theme of human-inspired manipulation. This chapter sought to embed observations seen from previous research [Eppner 15], thereby continuing along this human-inspired train of thought. The experiment conducted in the image above shows a human participant attempting to grasp a pair of glasses while their vision is impeded. The findings from this investigation saw an increase in environmental interaction. A natural extension to this observation is that we, as humans, tend to traverse along the environment with our fingers for a greater distance before closing into a grasp while leveraging the environment to improve grasp success. This fundamental notion is embedded into the reward function that the reinforcement learning algorithms use to learn the desired grasping motions.
Reinforcement Learning
The learning process uses two off-policy algorithms to learn the desired grasping motion on the gripper, where the actuators will move the fingertip to drag across a level surface before closing into a grasp. Such a formulation assumes that the gripper has pinned a flattened garment to the surface, as shown in the three images above. While such an act can initially seem simple, there are several complexities to consider, which previous approaches encountered. First, some authors noticed complexities regarding friction when their grippers interacted with different possible surfaces in the environment (e.g. [Koustoumpardis 14]). Such complexities sometimes prevented underactuated or tendon-driven motions from completing the grasping motion. In addition, none of the grippers who previously attempted similar grasping motions did so with a data-driven approach. They also could not perform these grasping motions from various wrist orientations.
An additional complexity associated with this learning problem is that grasping in this manner is a collision-rich motion, which, in addition to the friction as mentioned above complexities, requires both mechanisms for detecting collisions and safe servo control mechanisms for interacting with the environment without damaging the actuators. As the gripper already has a triaxial forcer embedded in the fingertip and uses the Dynamixel actuators with position and current command interfaces, the hardware setup suits this learning challenge. Lastly, the literature has also seen several successes in using RL for learning collision-rich robotic motion[Suomalainen 22, Elguea-Aguinaco 23].
Algorithms
I used two RL off-policy actor-critic algorithms to learn the desired grasping motions. Twin Delayed DDPG (TD3, [Fujimoto 18]) and Soft-Actor Critic (SAC, [Haarnoja 18c]) were breakthrough algorithms at their time of publication, which saw success in training several robotic skills in both locomotion and manipulation. This post will outline how these algorithms operate at a high level without delving too deep into the nuanced details. However, there are several profound complexities associated with both algorithms that the thesis details in depth.
First, the term off-policy refers to RL algorithms that train upon data external to the current policy. It can be simpler to describe off-policy algorithms as approaches that build a dataset of states, actions, new states, and rewards received and then use it to train the learning algorithm. Next, actor-critic refers to an algorithm with two key function approximators in its structure. An actor (or policy) takes in a state to produce an action. Next, the critic (or value function) takes in a state and action to produce a quality value, indicating the value of taking the action in a particular state. This function approximates neural networks that train to optimise the gripper’s behaviour to receive the maximum reward possible over time. While both algorithms are similar in certain elements, there are some slight differences that the next section outlines.
TD3
TD3 [Fujimoto 18] is an expansion of the Deep Deterministic Policy Gradient (DDPG) algorithm [Lillicrap 15], which initially presented an actor-critic algorithm applied to continuous action space problems and demonstrated such applicability. TD3 augmented DDPG by interacting with dual critic networks and taking the minimum estimation during training (clipped Q-Learning), thereby avoiding overestimation. They also slowed down the network updates such that the critic networks update more often than all others involved in the algorithm, reducing variance. Finally, TD3 applies target policy smoothing regularisation, meaning a clipped noise term is added to the actions taken by the target policy, which then updates the target critic networks. One of the primary distinctions of TD3, compared to SAC, is that TD3 uses a deterministic policy. Whereas SAC’s policy is stochastic.
SAC
SAC was released at approximately the same time as TD3 and can broadly be described as an actor-critic algorithm that utilises the maximum entropy framework (MEF). SAC learning directive is described as attempting to succeed at a task while acting as randomly as possible (thanks to the MEF incorporation). SAC achieves this goal by using an objective function incorporating an entropy measure term that encourages the policy to explore. Hyperparameter tuning can determine the impact of entropy upon learning. As mentioned in the previous section, SAC uses a stochastic policy. Thus, SAC gives an equal probability of optimal actions when multiple options are available. SAC underwent several iterations before landing on a specific version of the algorithm [Haarnoja 18], which automatically tuned the impact of entropy on learning and included several optimisations (partially inspired by TD3’s improvements upon DDPG).
Why these Algorithms?
While there are more complex and further algorithms to explore learning the desired grasping motions, TD3 and SAC have both shown success in learning skills like locomotion and manipulation and remain a strong starting point for exploring any new reward schema and learning formulation. In addition, this particular problem of learning motion behaviour based on sensor data and actuator behaviour has also been shown to slot nicely into TD3 and SAC, as they have been used as benchmarking algorithms for similar problems. In addition, off-policy algorithms (i.e. TD3 and SAC) tend to be more sample efficient than their on-policy counterparts (e.g. PPO), requiring fewer training steps to converge to a solution. Therefore, to evaluate the reward schema, environment, and training process, both algorithms were considered appropriate options to train the hand to perform the desired grasping motion.
Applying RL to the Gripper
Formulation
The first step of incorporating RL onto the gripper so that it can learn the desired grasping motions is the configuration of the learning formulation. First, I wanted to set the action vector, which dictates the commands sent from the policy to the gripper. As the gripper has eight possible command functions (4 actuators, each with two commands), the resultant eight-length vector had elements for each command. Next, the state vector requires definition. In this case, it combines the last actuator commands, the actuator motion details (position/velocity), the force sensor readings and the sensor’s position (the forward kinematics created in the previous post, t in the image below).
In addition to the state and action vectors, several parameters are defined to assist with the rewards scheme calculation. First, the coordinate frame h is defined on the static plate, as shown in the image below. Similarly to how the sensor’s position (t) is defined relative to a base coordinate frame w (see image below), h is also defined relative to w. By defining both the states and action vectors alongside the position of the static plate, we can now move onto the process of writing the reward function.
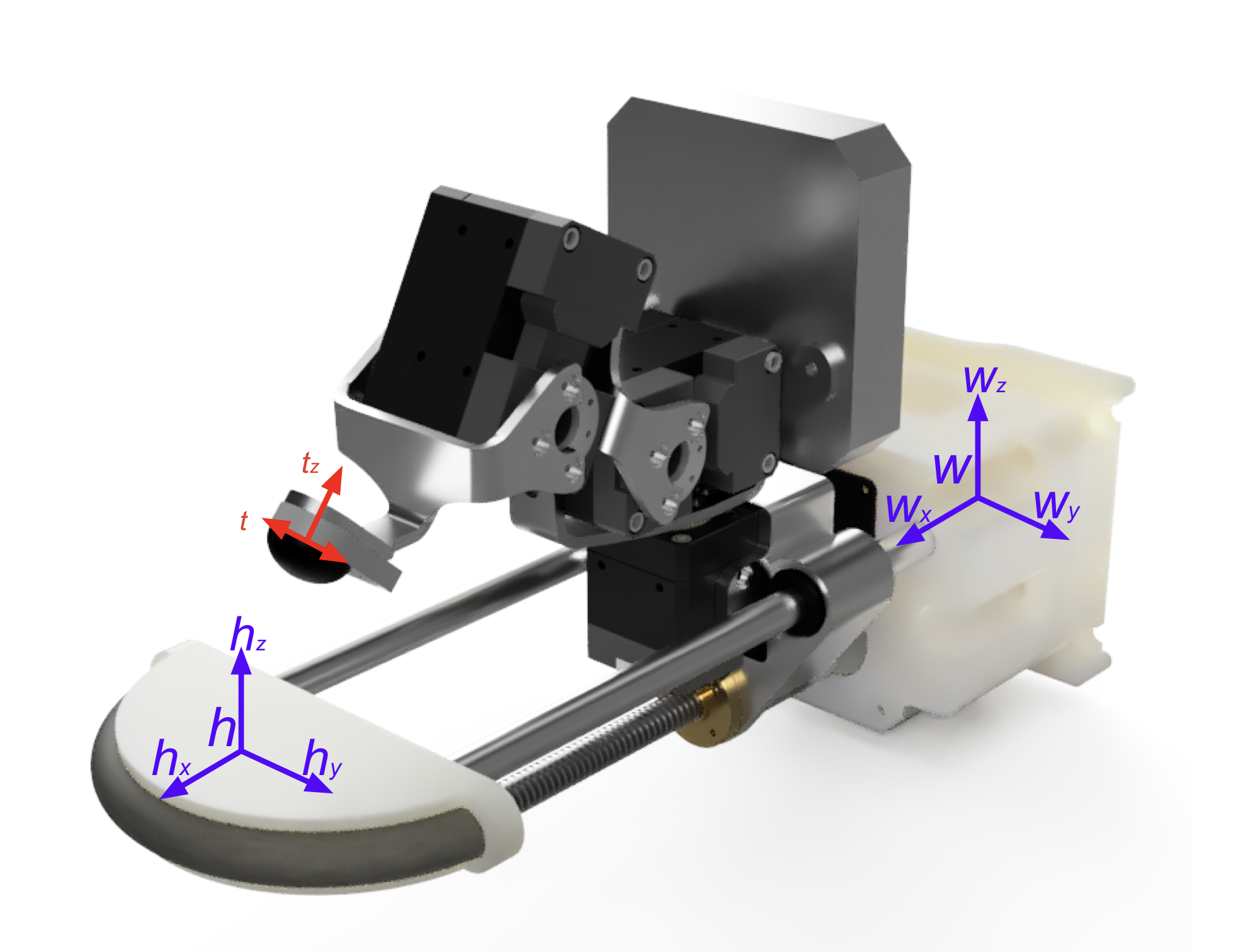
The gripper with custom defined coordinate frames needed for RL.
Writing the Reward Function
The next step was to write the reward function to encourage the gripper to drag along the environment before closing into a grasp. As previously mentioned, the reward schema considers that when we exploit the environment to grasp, our fingertips traverse across the environment surface for a greater distance than in a more traditional grasp action. In addition, the desired behaviour is to get the gripper’s fingertip to drag along the surface before closing into a grasp pose.
The coordinate frames h and t are used to measure parameters like the distance travelled, how close the gripper is to a grasp, and whether the gripper is in a grasping configuration. Additionally, the gripper uses readings from the force sensor and kinematics to determine if the gripper is in contact with the environment. In addition, the code hosting the reward function would track how far the fingertip has traversed the environment while in contact with the environment during a motion. The broad logic outlined below highlights the key aspects of the reward function.
- If the gripper makes contact with the environment, provide an initial reward.
- If the gripper moves inwards, i.e. moves t closer to h, while in contact with the environment, return a reward. If it moves outwards, return a penalising value.
- If the gripper abandons a traversing motion, return a penalising value.
- If the gripper closes into a grasp pose after traversing along the environment for a specific threshold value, return a final reward and flag that the trajectory has concluded.
Building the Environment
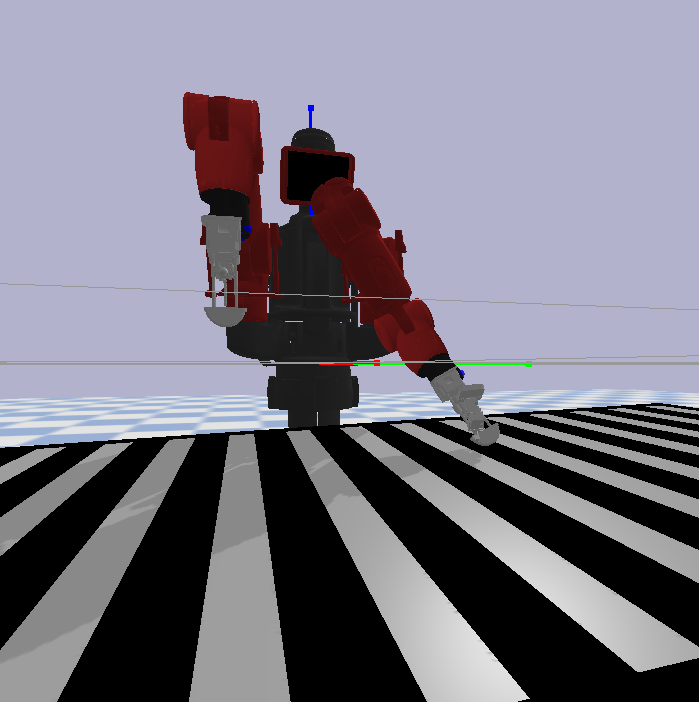
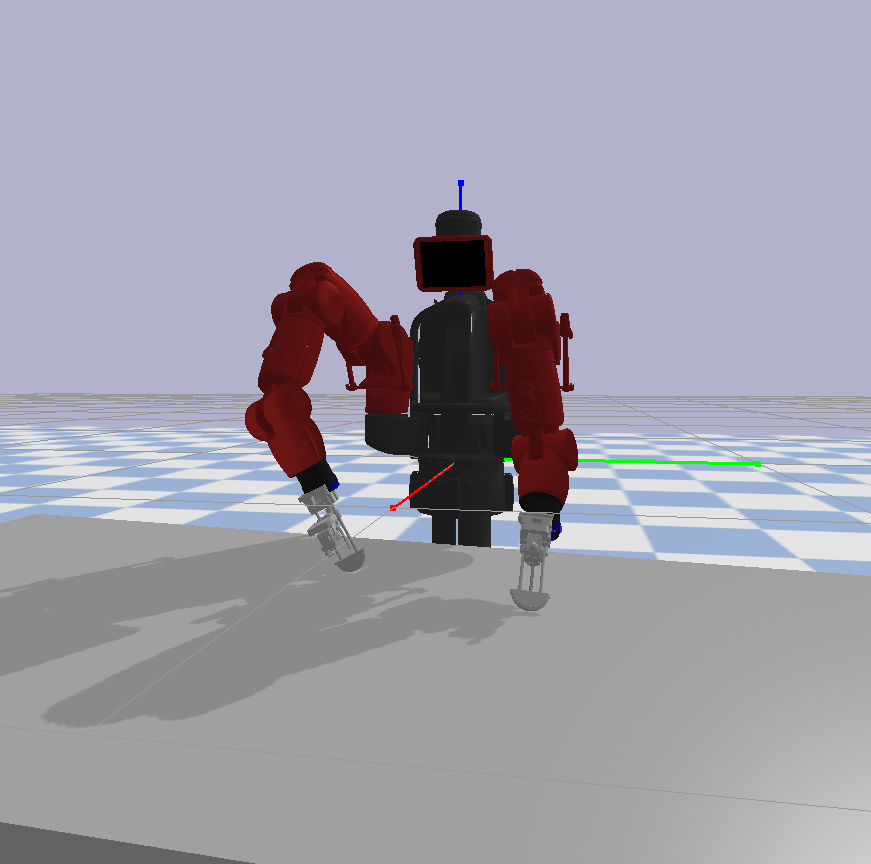
A fundamental part of any RL setup is establishing the environment and its variables. A common approach seen in robotics is first training a policy in simulation before deploying or improving the system in the real world, and I followed a similar format. In this case, a simulation in Pybullet was built to train upon. A URDF model of the gripper was attached to each arm of a Baxter model with a rigid surface placed in front of it. It should also be noted that, despite the intended applications for the learned grasping motions, the simulation does not contain clothing or deformable items. Simulating cloth or fabric still had some limitations when I was developing the environment, and a rigid body environment was sufficient for the proposed RL experiments.
The learning process is iterative, with the simulation using both grippers attached to the Baxter robot while executing learning trajectories. During training, one of the grippers attempts the grasping motion. Upon resetting, the gripper on the alternative Baxter arm performs another trajectory while the original arm is resetting its pose, i.e. colliding with the rigid surface. This iterative process continues throughout training, with both arms placing the gripper in a random pose for a new learning trajectory. This process can be observed in the video below.
An early example clip of the simulation training an off-policy algorithm.
Custom rigid surface bodies were converted into URDF files to serve as the surfaces for the training motions, ensuring that the learning process encounters diverse surfaces while learning the grasping motion. These surfaces are shown in the images below, with each coloured region having a different friction factor to further improve grasping generalisation. This crucial feature assisted in making the resulting policies highly generalisable to the friction dynamics between the gripper and the environment’s surface. The image below shows the various environment surfaces upon which training would occur. Every time the simulation restarts, the friction parameters of the environment are adjusted alongside a range of other dynamic parameters in the simulation. This alteration of dynamic properties while training is known as domain randomisation.


The simulated environment with a rigid surface showing differing friction surfaces/patterns.
Configuring the Learning Parameters
One of the most time-consuming and demanding parts of any learning process is ensuring that hyperparameters and configurations are set up to ensure that trained policies are robust and applicable. In this case, there was a wide range of parameters to consider, including crucial hyperparameters (e.g., the discount factor), neural network sizes, and domain randomisation parameters. The final values for the various parameters can be found in the thesis, and the images below show the final neural network structures used for both TD3 and SAC.
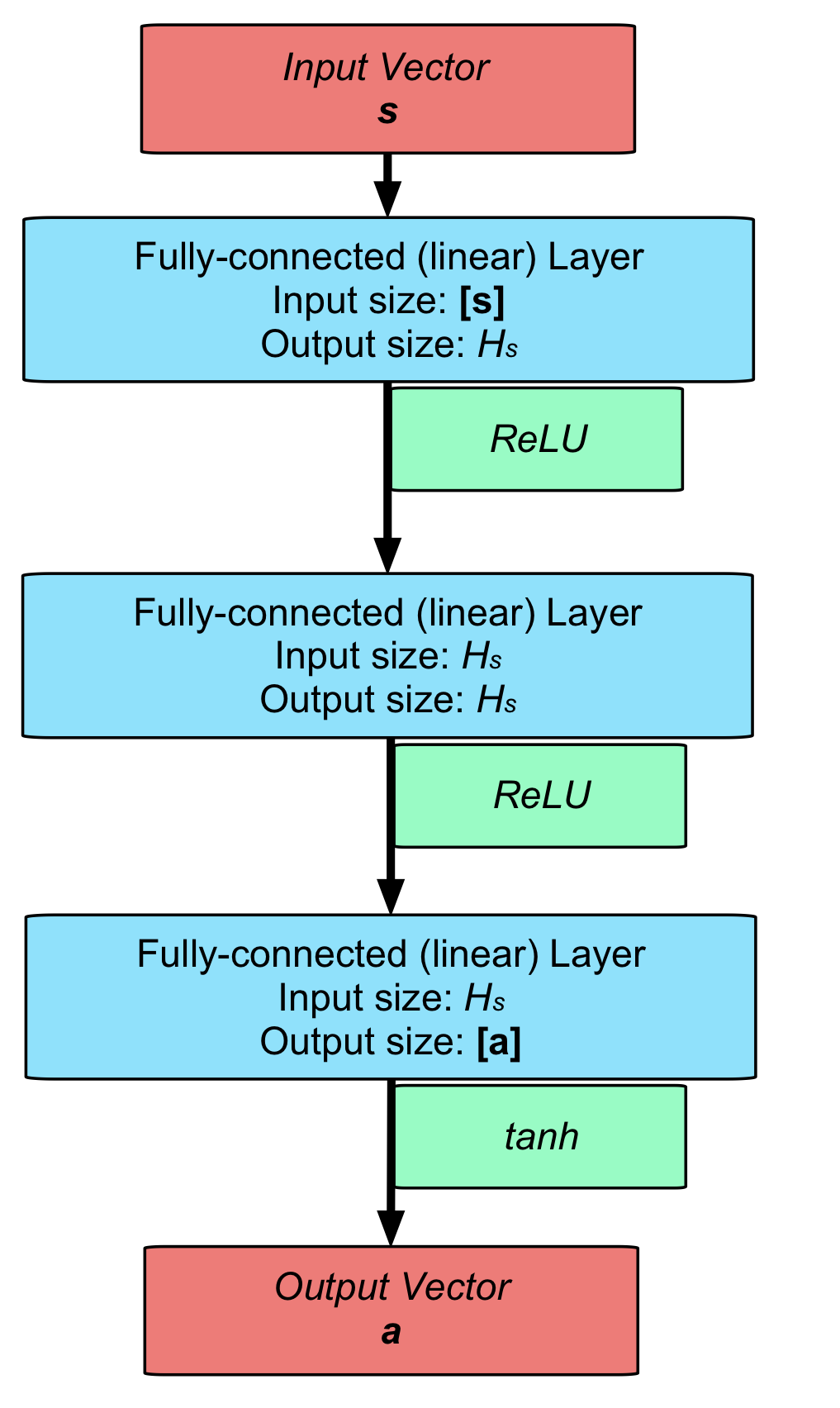
The actor network structure used for TD3.
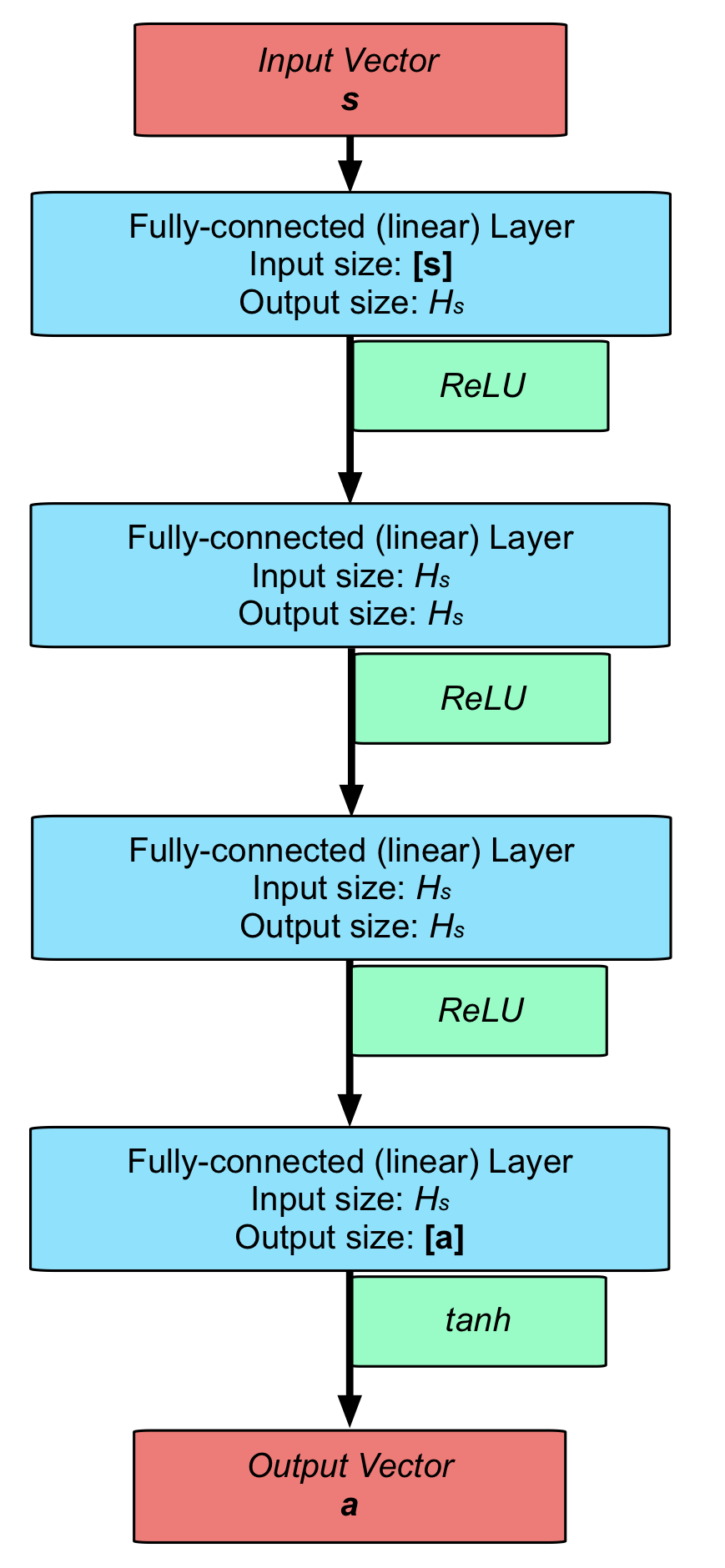
The actor network structure used for SAC.
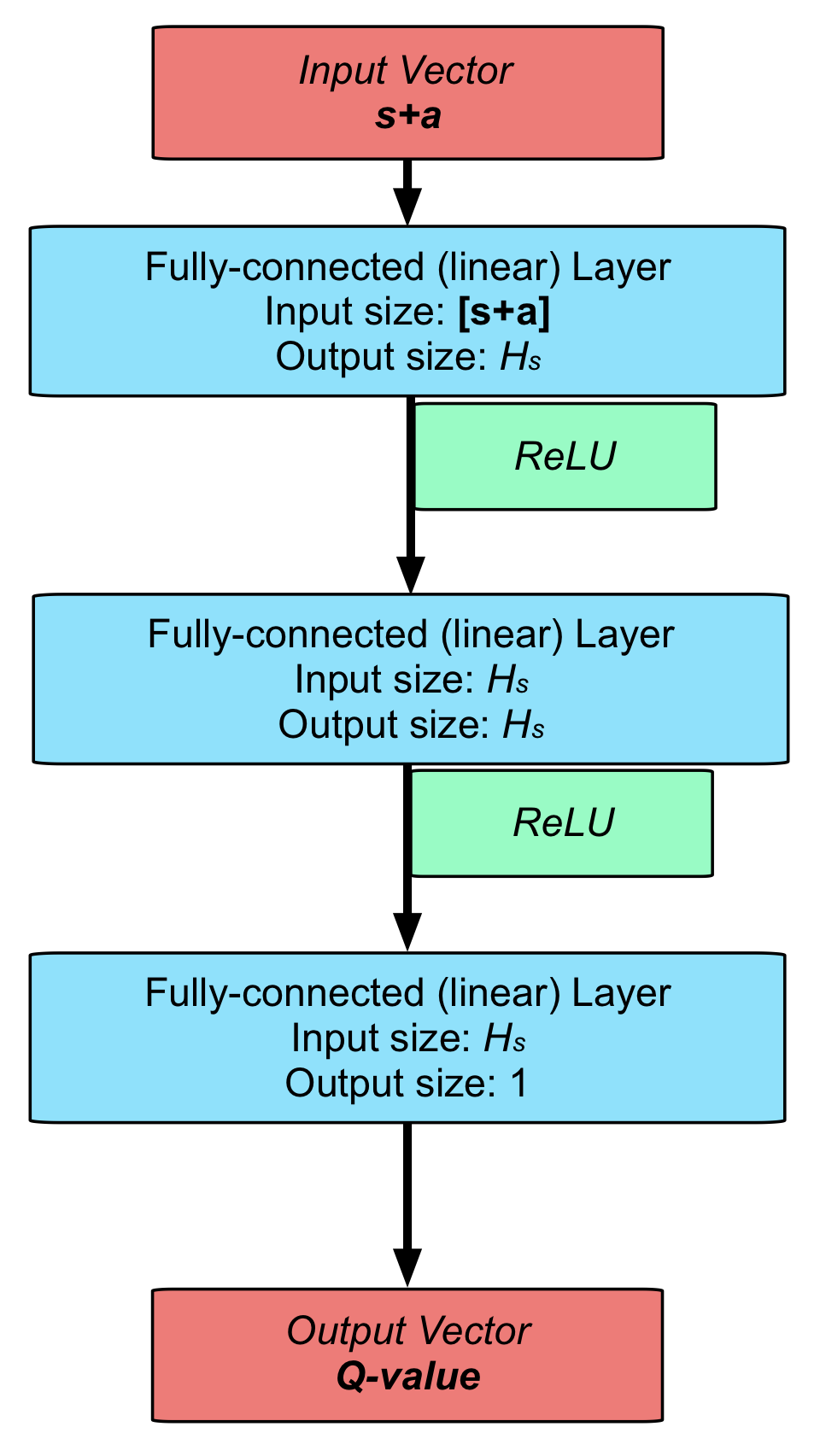
The critic network structure used for both algorithms.
Simulated Results
Both algorithms were trained in simulation across five training runs, and the images below show the results. Note that these results were the final training runs after several parameter-tuning iterations. Training both algorithms was time-intensive, with training runs taking at least 25 hours. The immediate observation shows that TD3 converged to a successful solution while SAC struggled to succeed.
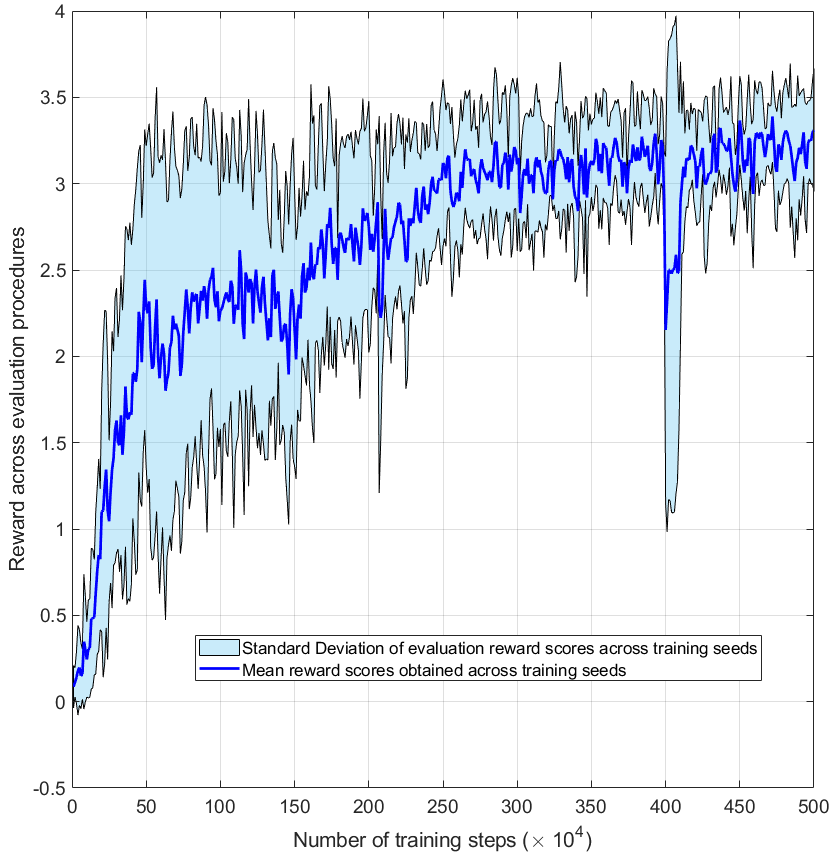
The TD3 training results across seeds.
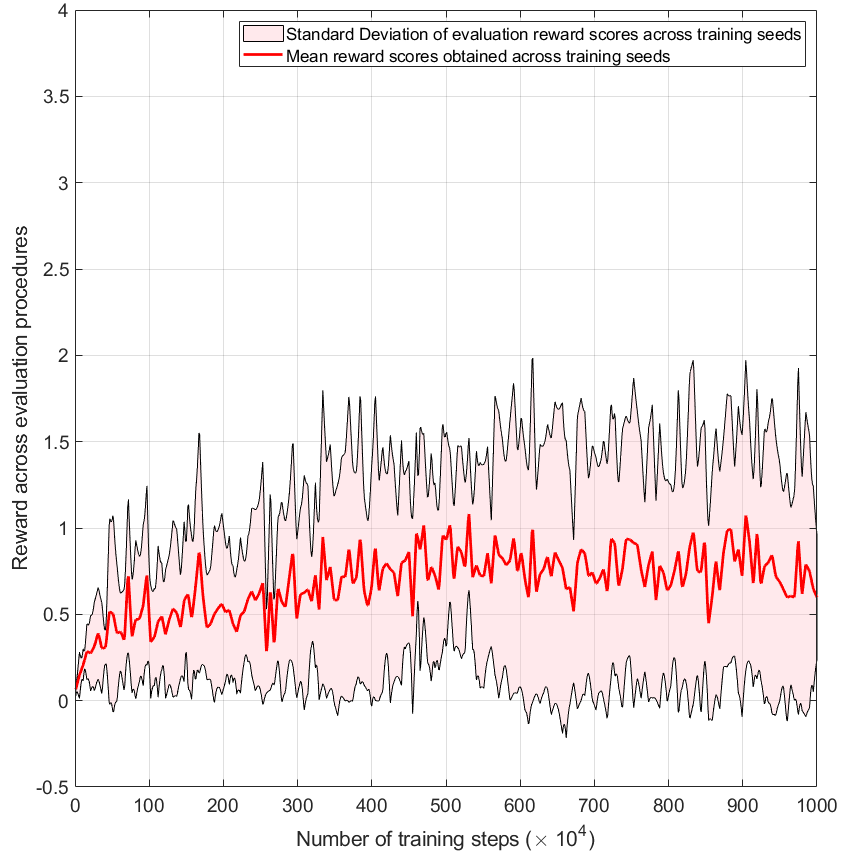
The SAC training results across seeds.
TD3’s capability of converging to a solution, while SAC struggles, could be due to several factors. First, SAC is an algorithm strongly emphasising exploration by incorporating the entropy term into the objective function. While beneficial in specific environments, this feature may have hindered learning the focal EC grasping motion of this research, which previous authors (incl. [Heinemann 15]) noted as relatively uniform motion behaviour despite the various wrist orientations. Furthermore, the deterministic policy of TD3 may have been advantageous if the learning of the EC grasping motion was a low-exploration problem.
It also remains possible and likely that I couldn’t find the correct set of hyperparameters and learning configurations to configure my implementation of SAC to this particular learning problem. When I evaluated my SAC implementation on benchmark environments from the python-gym environment, the training worked sufficiently well, converging to solutions for environments like the Ant or Walker2d. The simulation training processes also highlighted several limitations in the EC grasping environment that could benefit from improvement in future developments. First, the domain randomisation process used a pseudo-random number generator (PRNG) algorithm to alter environment dynamics after a reset. A hand-crafted approach to ensure a wide range of dynamic variable values may improve learning.
I also found limitations with the force sensor at the TCP on the hardware prototype, which exhibited non-linear mechanical responses in specific scenarios. As a result, adjustments were made in the simulator, restricting the cone of detection/operation. Such a limitation also made the training problem more difficult as forces could only be detected on a small sensor region (about a centimetre diameter cone). Despite these limitations, the learned policies under TD3 remain acceptable to evaluate on the hardware platform, grasping fabric using learned policies directly from the simulated environment.
Deploying to Hardware
Next, I applied one of the policies that had been successfully trained using TD3 and applied it to the real-world gripper. I want to evaluate how these learned grasping motions in the simulation translate to successfully grasping a flattened garment and observe any issues that might arise from a phenomenon known as the reality gap. Which is defined as an observed degradation in performance when directly transferring policies training simulation to hardware; a degradation in performance is usually observed.
This is why techniques such as domain randomisation are standard in RL; they expose a learning policy to a wide range of dynamic effects, which result in more robust policies that may reliably integrate into hardware. Several flattened garments of varying mechanical properties were evaluated to see if this grasping motion was applicable. The sequence of grasping a garment using the hardware is shown below, with the gripper grasping a scarf using the TD3-trained policy.





An example of the gripper grasping a scarf using the policy.
Using this policy, the success rate for picking flattened garments was approximately 88% across 288 hardware grasping trials. Overall, the results indicated that RL is a viable approach to teaching this grasping motion for garment handling. That being said, there were some limitations that further research could improve upon. Each grasping motion took around six seconds and usually required a few grasping attempts to succeed (as shown in the video below). The hardware evaluation also saw variance in successful grasp rates between garments, ranging between 71% and 96%. Demonstrating that the diverse mechanical behaviour of different garments/fabrics impacted grasping success in this particular experiment. Such issues need to be resolved before making this RL formulation practical. The following section outlines some final thoughts and approaches to improve the RL.
The trained TD3 policy applied on the hardware prototype.
Reflections and Future Work
Despite some limitations, seeing the gripper grasp clothing at such a high success rate is encouraging. Considering that these policies were trained in simulation only using rigid objects and no measures were taken to address limitations related to the realty gap, it is still encouraging to see these policies grasp flattened garments at such a high success rate when deployed to hardware. However, some limitations became apparent that should be addressed.
First, it remains possible that the challenges faced during the learning process are not due to deficiencies in the learning formulation but hardware limitations. First, the stepper-driven rail mechanism was an open-loop actuator system, which could have caused a degradation of position measurement accuracy during the hardware evaluation. As previously mentioned, some complex force sensor behaviour was challenging to integrate into the simulation, and concessions were made to accommodate the sensor, resulting in a limited sensing area. An investigation into developing a setup that more closely reflects the tactile sensing range of human hands could be an exciting avenue to explore to improve this learning of EC motion.
Alternatively, exploring other RL algorithms, such as on-policy approaches or integrating vision into a broader RL pipeline, could be a compelling exploration avenue. It would be interesting to further explore if other algorithms attempting to learn this EC grasping motion suffer from the same limitation seen by SAC or whether hyperparameter optimisation could improve SAC’s performance. Additionally, if one were to create a more refined sensing structure on hand, integrating goal-based RL onto the system, i.e. training policies to perform the grasping motion while dictating how much force to apply on the environment surface with the finger dragging along the surface. That’s a challenge that I find really interesting, learning such a refined level of robotic control during a complex collision-rich motion.
This body of work was the final chapter of my doctorate research, and I really enjoyed the process. The broad implications of this RL research indicate that EC grasping of a single flattened garment is a challenge solvable via data-driven approaches. Despite the limitations seen, it is definitely a foundation upon which to build.
Use this link to view the final post surrounding my PhD project. This is a concluding post about my PhD project and a reflection on the lessons learnt.
References
[Elguea-Aguinaco 23] Inigo Elguea-Aguinaco, Antonio Serrano-Munoz, Dimitrios Chrysostomou, Ibai Inziarte-Hidalgo, Simon Bøgh, and Nestor Arana-Arexolaleiba. “A review on reinforcement learning for contact-rich robotic manipulation tasks”. Robotics and Computer-Integrated Manufacturing, 81:102517, 2023.
[Eppner 15] Clemens Eppner, Raphael Deimel, Jose Alvarez-Ruiz, Marianne Maertens, and Oliver Brock. “Exploitation of environmental constraints in human and robotic grasping”. The International Journal of Robotics Research, 34(7):1021–1038, 2015
[Fujimoto 18] Scott Fujimoto, Herke Hoof, and David Meger. “Addressing function approximation error in actor-critic methods”. In International Conference on Machine Learning, pages 1587–1596. PMLR, 2018.
[Haarnoja 18] Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905, 2018.
[Heinemann 15] Fabian Heinemann, Steffen Puhlmann, Clemens Eppner, Jose Elvarez-Ruiz, Marianne Maertens, and Oliver Brock. A taxonomy of human grasping behavior suitable for transfer to robotic hands. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pages 4286–4291. IEEE, 2015.
[Kazemi 14] Moslem Kazemi, Jean-Sebastien Valois, J Andrew Bagnell, and Nancy Pollard. “Human inspired force compliant grasping primitives”. Autonomous Robots, 37(2):209–225, 2014
[Koustoumpardis 14] Panagiotis N Koustoumpardis, Kostas X Nastos, and Nikos A Aspragathos. “Underactuated 3-finger robotic gripper for grasping fabrics”. In 2014 23rd International Conference on Robotics in Alpe-Adria-Danube Region (RAAD), pages 1–8. IEEE, 2014.
[Puhlmann 16] Steffen Puhlmann, Fabian Heinemann, Oliver Brock, and Marianne Maertens. “A compact representation of human single-object grasping”. In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1954–1959. IEEE, 2016.
[Santina 17] Cosimo Della Santina, Matteo Bianchi, Giuseppe Averta, Simone Ciotti, Visar Arapi, Simone Fani, Edoardo Battaglia, Manuel Giuseppe Catalano, Marco Santello, and Antonio Bicchi. “Postural hand synergies during environmental constraint exploitation”. Frontiers in Neurorobotics, 11:41, 2017.
[Sarantopoulos 18] Iason Sarantopoulos and Zoe Doulgeri. “Human-inspired robotic grasping of flat objects”. Robotics and Autonomous Systems, 108:179–191, 2018.
[Suomalainen 22] Markku Suomalainen, Yiannis Karayiannidis, and Ville Kyrki. “A survey of robot manipulation in contact. Robotics and Autonomous Systems”, 156:104224, 2022.